딥러닝 면접 질문 : sigmoid 대신 ReLU를 사용하는 이유가 뭔가요?
sigmoid 대신 ReLU를 사용하는 이유가 뭔가요?
추가질문 1. ReLU는 미분 불가능한데 BP(backpropagation)가 어떻게 가능한가요?
추가질문 2. Leaky-ReLU는 무엇인가요?
[ReLU의 대표적인 장점]
- Sparsity
- Vanishing Gradient
위 장점은 sigmoid 함수와의 비교했을 때 이다.
ReLU가 나오기 전에는 주로 sigmoid가 많이 쓰였으므로 sigmoid와 비교하는 것이 옳다.
sigmoid는 tanh와 비슷한 경향이 있다. 단, tanh는 sigmoid에 비해 Vanishing Gradient가 개선된 경우이지 극복한 것은 아니다.
[ReLU를 사용하는 이유]
1) Sparsity (a(활성화값)가 0보다 작을 때 / a≤0)
(Sparse 하다는 것은?)
sparse하다는 뜻은 벡터를 표시하는 값들 중에 0이 많은 수를 차지한다는 것, 즉 값이 비어있다는 뜻이다. 그 반대는 값이 차있는 dense한 경우라고 표현한다. (one hot vector는 매우 sparse하다고 볼 수 있고, embedding vector는 dense하다고 볼 수 있다.)
(Sparsity가 유용한 이유)
활성화 값(a)이 0보다 작은 뉴런들이 많을수록 더욱 더 sparse한 모습을 띄게 된다. 하지만 기본적으로 (혹은 전통적으로) neural network에서 사용해온 sigmoid 함수는 항상 0이 아닌 어떠한 값(eg. 0.2, 0.01, 0.003 …)을 만들어내는 경향이 있어 dense한 모습을 나타내게 된다.
뉴런의 활성화값이 0인 경우, 어차피 다음 레이어로 연결되는 weight를 곱하더라도 결과값은 0을 나타내게 되서 계산할 필요가 없기에 sparse한 형태가 dense한 형태보다 더 연산량을 월등히 줄여준다. (하지만 0으로 한번 할당되면 다시 활성화 되지 않으므로 해당 뉴런을 dead neuron / dying Relu 이라고 표현하기도 한다.)

단, 0보다 작은 값들에서 뉴런이 죽을 수 있는 것은 단점으로도 작용할 수 있다. –> leaky relu가 보완해준다.
2) Vanishing Gradient (a가 0보다 클 때 / a>0)
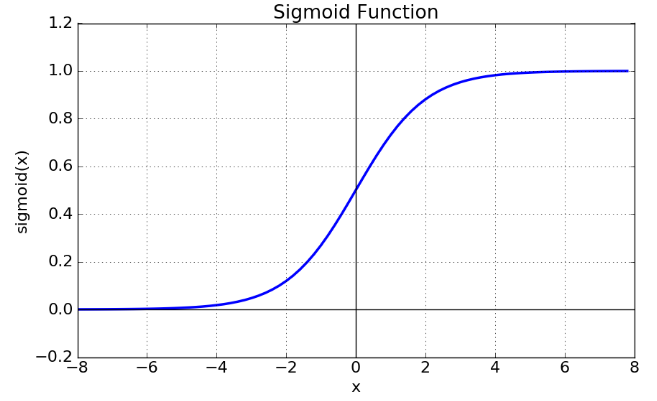
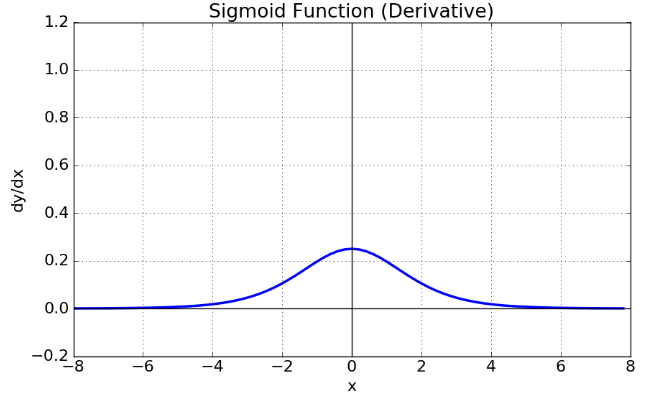
sigmoid 함수 (상) & sigmoid 도함수 (하)
Sigmoid 함수는 음수 값을 0에 가깝게 표현하기 때문에 입력 값이 최종 레이어에서 미치는 영향이 적어지는 Vanishing Gradient Problem이 발생한다.
Sigmoid 도함수 그래프에서 미분 계수를 보면 최대값이 0.25이다.딥러닝에서 학습을 위해 Back-propagation을 계산하는 과정에서 활성화 함수의 미분 값을 곱하는 과정이 포함되는데, Sigmoid 함수의 경우 은닉층의 깊이가 깊으면 오차율을 계산하기 어렵다는 문제가 발상하기 때문에, Vanishing Gradient Problem이 발생한다.
다시 말해, x의 절대값이 커질수록 Gradient Backpropagation 시 미분 값이 소실될 가능성이 큰 단점이 있다. 또한, Sigmoid 함수의 중심이 0이 아닌데, 이 때문에 학습이 느려질 수 있는 단점이 있다.
한 노드에서 모든 파라미터의 미분 값은 모두 같은 부호를 같게 되는데, 같은 방향으로 update되는 과정은 학습을 지그재그 형태로 만드는 원인을 낳는다.
이러한 문제 때문에 딥러닝 실무에서는 잘 사용되지 않지만, 미분 결과가 간결하고 사용하기 쉽기 때문에 입문 단계에서 꼭 다루는 함수이다.
모든 실수 값을 0보다 크고 1보다 작은 미분 가능한 수로 변환하는 특징을 같이 때문에, Logistic Classification과 같은 분류 문제의 가설과 비용 함수(Cost Function)에 많이 사용된다.
또한 sigmoid()의 리턴 값이 확률 값이기 때문에 결과를 확률로 해석할 때 유용하다.
반면 sigmoid의 gradient는 x의 절댓값이 증가하는 만큼 작아지게 되는 것에 비해, ReLU의 역함수는 1이므로 ReLU의 경우에는 gradient로 상수를 갖게된다. 일정한 gradient값은 빠르게 학습하는 것을 도와주고 Vanishing Gradient Problem이 발생하지 않는다.
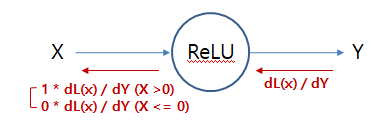
relu 함수의 역전파(Back Propagation)는 어떻게 될까요??
그냥 있는 그대로 x의 값을 기준으로 나뉘게 됩니다.
df(x)/dx = 1 (x > 0)
= 0 (x <= 0)
이렇게 되고, 순전파때 x가 0보다 클 경우 역전파는 Loss Function에 대한 미분결과를 그대로 돌려주고, x가 0보다 작으면 역전파는 0이 됩니다.
leaky-Relu
Leaky ReLUU는 ReLU가 갖는 Dying ReLU(뉴런이 죽는 현상) 을 해결하기 위해 나온 함수이다.
함수도 아래와 같이 매우 간단한 형태로 정의된다.
f(x) = max(0.01x,x)
0.01이 아니라 매우 작은 값이라면 무엇이든 사용 가능하다.
Leaky ReLU는 x가 음수인 영역의 값에 대해 미분값이 0이 되지 않는다는 점을 제외하면 ReLU의 특성을 동일하게 갖는다.
추가, tanh
Hyperbolic Tangent Function은 쌍곡선 함수 중 하나로, Sigmoid 함수를 변형해서 얻을 수 있다.
tanh(x) = ( e^x - e^-x ) / ( e^x + e^-x )
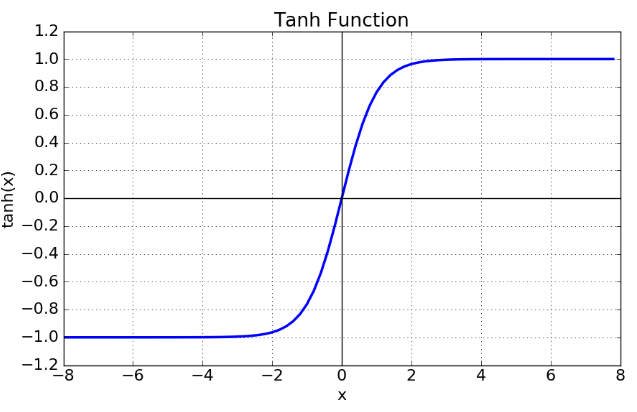
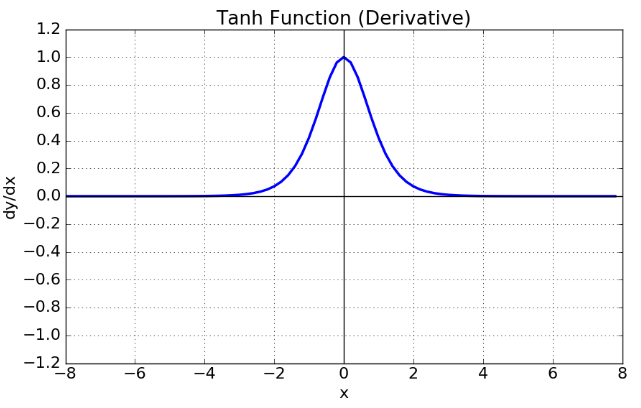
tanh 함수 (상) & tanh 도함수 (하)
tanh 함수는 함수의 중심점을 0으로 옮겨 sigmoid가 갖고 있던 최적화 과정에서 느려지는 문제를 해결했다.
하지만 미분함수에 대해 일정 값 이상에서 미분 값이 소실되는 Vanishing Gradient Problem은 여전히 남아있다.
참고 사이트
- https://joonable.tistory.com/2
- https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=handuelly&logNo=221824080339
- https://ayoteralab.tistory.com/entry/ANN-10-%ED%99%9C%EC%84%B1%ED%99%94%ED%95%A8%EC%88%98s-Back-Propagation-ReLU-Sigmoid
