내가 다시 보려고 만든 “밑바닥 부터 시작하는 딥러닝” 정리 2
책 “밑바닥부터 시작하는 딥러닝 1권” 내용 중 다시 보려고 만든 자료입니다. (챕터 4)
chapter 4
- 챕터 4의 주제는 신경망 학습이다. 여기서 학습이란 훈련 데이터로부터 가중치 매개변수의 최적값을 자동으로 획득하는 것을 뜻한다.
- 이번 챕터에서는 신경망이 학습할 수 있도록 해주는 지표인 손실 함수를 소개한다. 이 손실 함수의 결괏값을 가장 작게 만드는 가중치 매개변수를 찾는 것이 학습의 목표이다.
chapter 4.1 : 데이터에서 학습한다.
- 신경망은 이미지를 ‘있는 그대로’ 학습한다. 신경망은 이미지에 포함된 중요한 특징까지도 “기계”가 스스로 학습할 것이다.
- 딥러닝을 종단간 기계학습이라고 한다. 데이터(입력)에서 목표한 결과(출력)를 사람의 개입 없이 얻는다는 뜻을 담는다.
- 신경망의 이점은 모든 문제를 같은 맥락에서 풀 수 있다는 점에 있다.
- 어떤 객체를 인식하든, 세부사항과 관계없이 신경망은 주어진 데이터를 온전히 학습하고, 주어진 문제의 패턴을 발견하려 시도한다.
- 즉, 신경망은 모든 문제를 주어진 데이터 그대로를 입력 데이터로 활용해 ‘end-to-end’로 학습할 수 있다.
chapter 4.2 : 손실 함수
- 신경망도 ‘하나의 지표’를 기준으로 최적의 매개변수 값을 탐색한다. 신경망 학습에서 사용하는 지표는 손실 함수라고 한다.
일반적으로는 오차제곱합과 교차 엔트로피 오차를 사용한다.
- 오차 제곱합
- 가장 많이 쓰이는 손실함수는 오차제곱합(SSE, sum of squares for error)이다.

yk 는 신경망의 출력(신경망이 추정한 값), tk는 정답 레이블, k는 데이터의 차원 수
- 교차 엔트로피 오차

여기서 log는 밑이 e인 log함수, yk는 신경망의 출력, tk는 정답 레이블
실질적으로 정답일 때의 추정(tk가 1일때의 yk)의 자연로그를 계산하는 식이 된다.
- 미니배치 학습
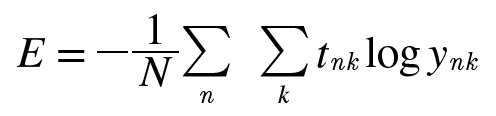
데이터가 N개라면 tnk는 n번째 데이터의 k번째 값을 의미합니다.(ynk는 신경망의 출력, tnk는 정답레이블)
평균 손실 함수를 구하는것.
- 그러나, 학습 데이터의 양이 매우 방대해지면 손실 함수의 합을 구하는데 시간이 좀 걸린다. 이 많은 데이터를 대상으로 일일이 손실 함수를 계산하는 것은 현실적이지 않다.
- 데이터를 일부를 추려 전체의 ‘근사치’로 이용할 수 있다. 신경망 학습에서도 훈련데이터로부터 일부만 골라 학습을 수행하는데 이 일부를 미니배치라고 한다.
- 예를 들어, 60000만장의 훈련 데이터 중에서 100장을 무작위로 뽑아 그 100장만을 사용하여 학습하는 것이다. 이러한 학습 방법을 미니배치 학습이라고 한다.
chapter 4.2.5 : 왜 손실 함수를 설정하는가 ?
- 왜 굳이,,, 손실 함수를 사용할까 ? ‘정확도’라는 지표를 놔두고 ‘손실 함수의 값’이라는 우회적인 방법을 택하는 이유는 뭘까 ?
- 이 의문은 신경망 학습에서의 ‘미분’의 역할에 주목한다면 해결된다. 신경망 학습에서는 최적은 매개변수(가중치와 편향)를 탐색할 때 손실 함수의 값을 가능한 작게 하는 매개변수 값을 찾는다.
- 가중치 매개변수의 손실 함수의 미분이란 ‘가중치 매개변수의 값을 아주 조금 변화 시켰을 때, 손실 함수가 어떻게 변하나’라는 의미이다.
- if 미분 값 < 0 ( > 0 ) , 가중치 매개변수를 양의 방향(음의 방향)으로 변화
if 미분 값 = 0 , 가중치 매개변수를 어느 쪽으로 움직여도 손실 함수의 값은 줄어들지 않는다. = 가중치 매개변수의 갱신은 멈춘다.
- “정확도를 지표로 삼아서는 안 되는 이유는 미분 값이 대부분의 장소에서 0이 되어 매개변수를 갱신할 수 없기 때문이다.”
그러면 대부분의 장소에서 0이 되는 이유는 무엇일까? 정확도가 55% 였을때, 매개변수를 약간만 조정해서는 정확도가 개선되지 않고 일정하게 유지된다. 또는 개선된다 하더라도 55.2334%와 같이 연속적인 변화가 아니라 54%, 56%처럼 불연속적인 띄엄띄엄한 값으로 바뀐다.
반면에 손실함수를 지표로 삼는다면, 매개변수의 값이 조금 변하면 그에 반응하여 손실 함수의 값도 연속적으로 변화한다.
- 정확도는매개변수의 미소한 변화에는 거의 반응을 보이지 않고, 반응이 있더라도 그 값이 불연속적으로 갑자기 변화한다. (계단함수를 사용하지 않는 이유이기도 하다.)
chapter 4.4.1 : 경사법(경사 하강법)
- 기계학습 문제 대부분은 학습 단계에서 최적의 매개변수를 찾아낸다. 신경망 역시 최적의 매개변수(가중치와 편향)를 학습시에 찾아야 한다. 여기에서 최적이란 손실 함수가 최솟값이 될 때의 매개변수 값이다.
- 그러나 일반적 문제의 손실 함수는 매우 복잡하다. 이때 기울기를 잘 이용해 함수의 최솟값(또는 가능한 한 작은 값)을 찾으려는 것이 경사법이다.
- 경사법은 현 위치에서 기울어진 방향으로 일정 거리만큼 이동한다. 그런 다음 이동한 곳에서도 마찬가지로 기울기를 구하고, 또 그 기울어진 방향으로 나아가기를 반복한다. 이렇게 해서 함수의 값을 점차 줄이는 것이 경사법이다.
- 경사법을 수식으로

η(에타)는 갱신하는 양을 나타낸다. 이를 신경망에서는 학습률이라고 한다.
한번의 학습으로 얼마만큼 학습해야 할지, 즉 매개변수 값을 얼마나 갱신하느냐를 정하는 것이 학습률이다.
chapter 4.4.1 : 신경망에서의 기울기
- 신경망 학습에서도 기울기를 구해야 한다. 여기서 말하는 기울기는 가중치 매개변수에 대한 손실 함수의 기울기이다.
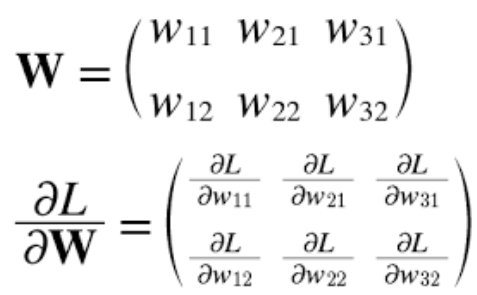
가중치가 W, 손실 함수가 L
가중치를 조금 변경했을 때, 손실 함수 L이 얼마나 변화하느냐를 나타낸다.
chapter 4.5 : 학습 알고리즘 구현하기
- 전제 : 신경망에는 적용 가능한 가중치와 편향이 있고, 이 가중치와 편향을 훈련 데이터에 적응하도록 조정하는 과정을 ‘학습’이라고 한다. 신경망 학습은 다음 4단계로 수행한다.
- 미니배치 : 훈련 데이터 중 일부를 무작위로 가져옵니다. 이렇게 선별한 데이터를 미니배치라 하며, 그 미니배치의 손실 함수 값을 줄이는 것이 목표다.
- 기울기 산출 : 미니배치의 손실 함수 값을 줄이기 위해 각 가중치 매개변수의 기울기를 구합니다. 기울기는 손실 함수의 값을 가장 작게 하는 방향을 제시합니다.
- 매개변수 갱신 : 가중치 매개변수를 기울기 방향으로 아주 조금 갱신합니다.
- 반복 : 1~3 단계를 반복합니다.
이는 경사 하강법으로 매개변수를 갱신하는 방법이며, 이때 데이터를 미니배치로 무작위로 선정하기 때문에 확률적 경사 하강법(SGD)라고 부릅니다. ‘확률적으로 무작위로 골라낸 데이터’에 대해 수행하는 경사하강법이라는 의미이다.
수치 미분 방식으로 매개변수의 기울기를 계산하는 방법을 사용했다. chapter 5에서는 이 기울기 계산을 고속으로 수행하는 기법을 설명한다. 그 방법은 오차역전파법이다. 오자역전파법을 사용하면 수치 미분을 사용할 때와 거의 같은 결과를 훨씬 빠르게 얻을 수 있다.
chapter 4.5.3
- 에폭 : 에폭은 하나의 단위입니다. 1에폭은 학습에서 훈련 데이터를 모두 소진했을 때의 횟수에 해당한다. 예를 들어, 훈련 데이터 10000개를 100개의 미니배치로 학습할 경우, 확률적 경사하강법을 100회 반복하면 모든 훈련 데이터를 소진한게 된다. 이 경우 100회가 1에폭이 된다.
